


📊 Un Flujo de Trabajo basado en IA para Resolver la Canibalización de Contenidos
🎫Prueba mi flujo de trabajo de IA gratuito, evita los mitos de la canibalización y prueba el detector de canibalización de contenidos automatizado.

Un Flujo de Trabajo basado en IA para Resolver la Canibalización de Contenidos
Por: Kevin Indig, que ha pasado 10 años como operador y líder en empresas de rápido crecimiento como Shopify, G2 y Atlassian. Desde mediados de 2022, ha sido asesor independiente de empresas emergentes de hipercrecimiento como Meta, Reddit, Ramp, Bounce, Snapchat, Dropbox, Toast y Nextdoor. Escribe Growth Memo, una newsletter para personas interesadas en la intersección entre marketing y estrategia empresarial.
Es probable que tu sitio sufra al menos algo de canibalización de contenido, y puede que ni siquiera te des cuenta.
La canibalización perjudica el tráfico orgánico y los ingresos: el impacto puede ir desde páginas clave que no se posicionan hasta problemas de algoritmo debido a la baja calidad del dominio.
Sin embargo, la canibalización es difícil de detectar, puede cambiar con el tiempo y existe en un espectro.
Es el «microplástico del SEO».
En este memorándum, te mostraré:
Cómo identificar y corregir la canibalización de contenido de manera fiable
Cómo automatizar la detección de canibalización de contenido
Un flujo de trabajo automatizado que puedes poner a prueba ahora mismo: El Detector de Canibalización, mi nueva herramienta de canibalización de palabras clave
Nunca podría haber hecho esto sin Nicole Guercia de AirOps. Yo diseñé el concepto y realicé pruebas de estrés del flujo de trabajo automatizado, pero Nicole construyó todo el sistema.
Cómo pensar en la canibalización de contenido de la manera correcta
Antes de entrar en materia, debemos aclarar algunos principios rectores sobre la canibalización de contenidos que a menudo se malinterpretan.
La idea errónea más extendida sobre la canibalización es que ocurre a nivel de palabras clave.
En realidad, ocurre a nivel de la intención del usuario.
Todos debemos dejar de pensar en este concepto como canibalización de palabras clave y, en su lugar, como canibalización de contenidos basada en la intención del usuario.
Teniendo esto en cuenta, la canibalización...
Es un objetivo en movimiento: cuando Google actualiza su comprensión de la intención durante una actualización principal, de repente dos páginas que antes no competían entre sí pueden hacerlo.
Existe en un espectro: una página puede competir con otra página o varias páginas, con una superposición de intención del 10 % al 100 %. Es difícil decir exactamente cuánta superposición está bien sin mirar los resultados y el contexto.
No se limita a las clasificaciones: Buscar dos páginas que obtengan una cantidad «sustancial» de impresiones o clasificaciones para las mismas palabras clave puede ayudarte a detectar la canibalización, pero no es un método muy preciso. No es prueba suficiente.
Necesita revisiones periódicas: Debes revisar tu sitio con regularidad para detectar la canibalización y tratar tu biblioteca de contenido como un ecosistema «vivo».
Puede ser engañoso: muchos casos no están claros. Por ejemplo, la canibalización de contenido internacional no es obvia. Un directorio /en para dirigirse a todos los países de habla inglesa puede competir con un directorio /en-us para el mercado estadounidense.
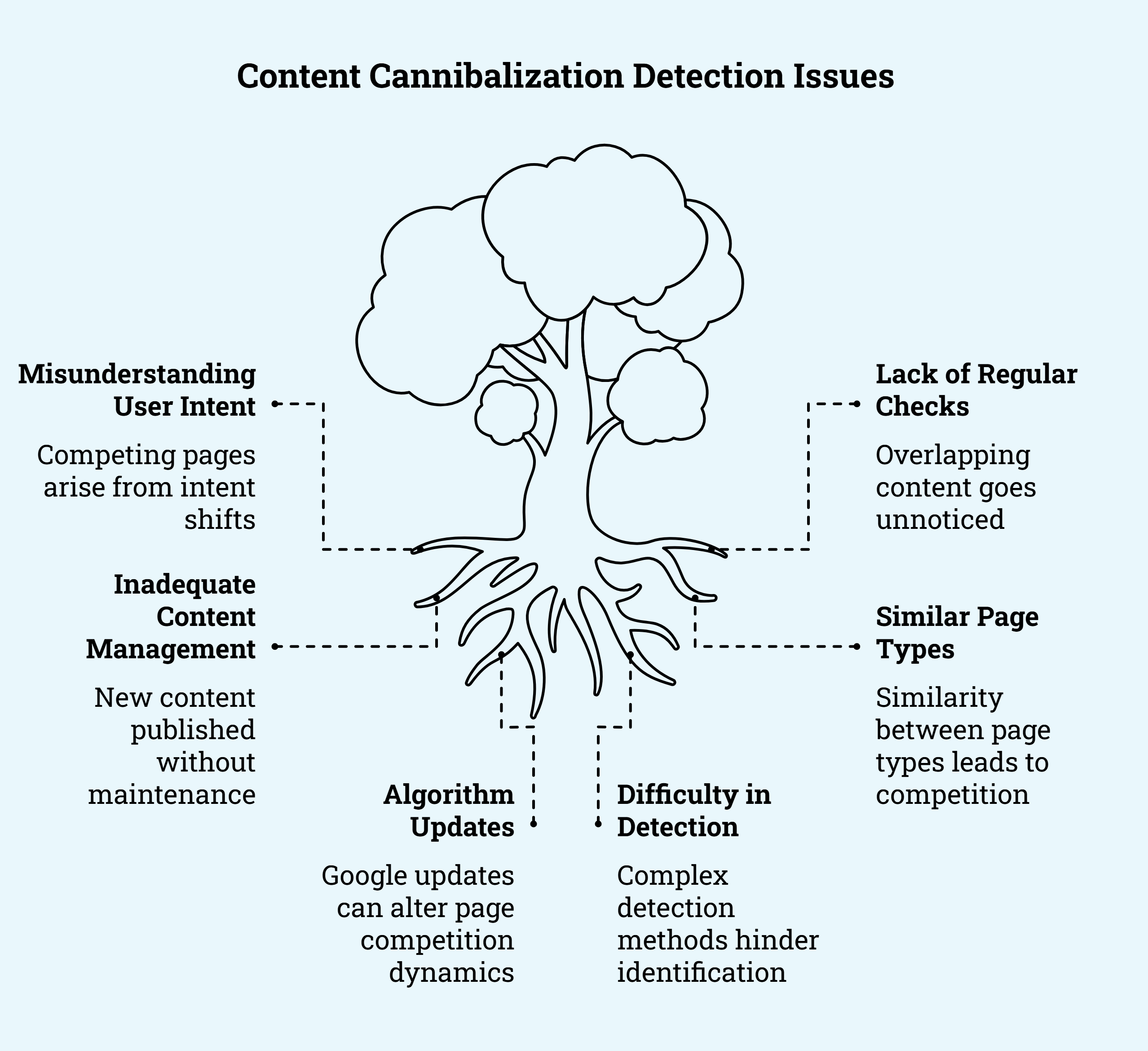
Los diferentes tipos de sitios tienen debilidades fundamentalmente diferentes para la canibalización.
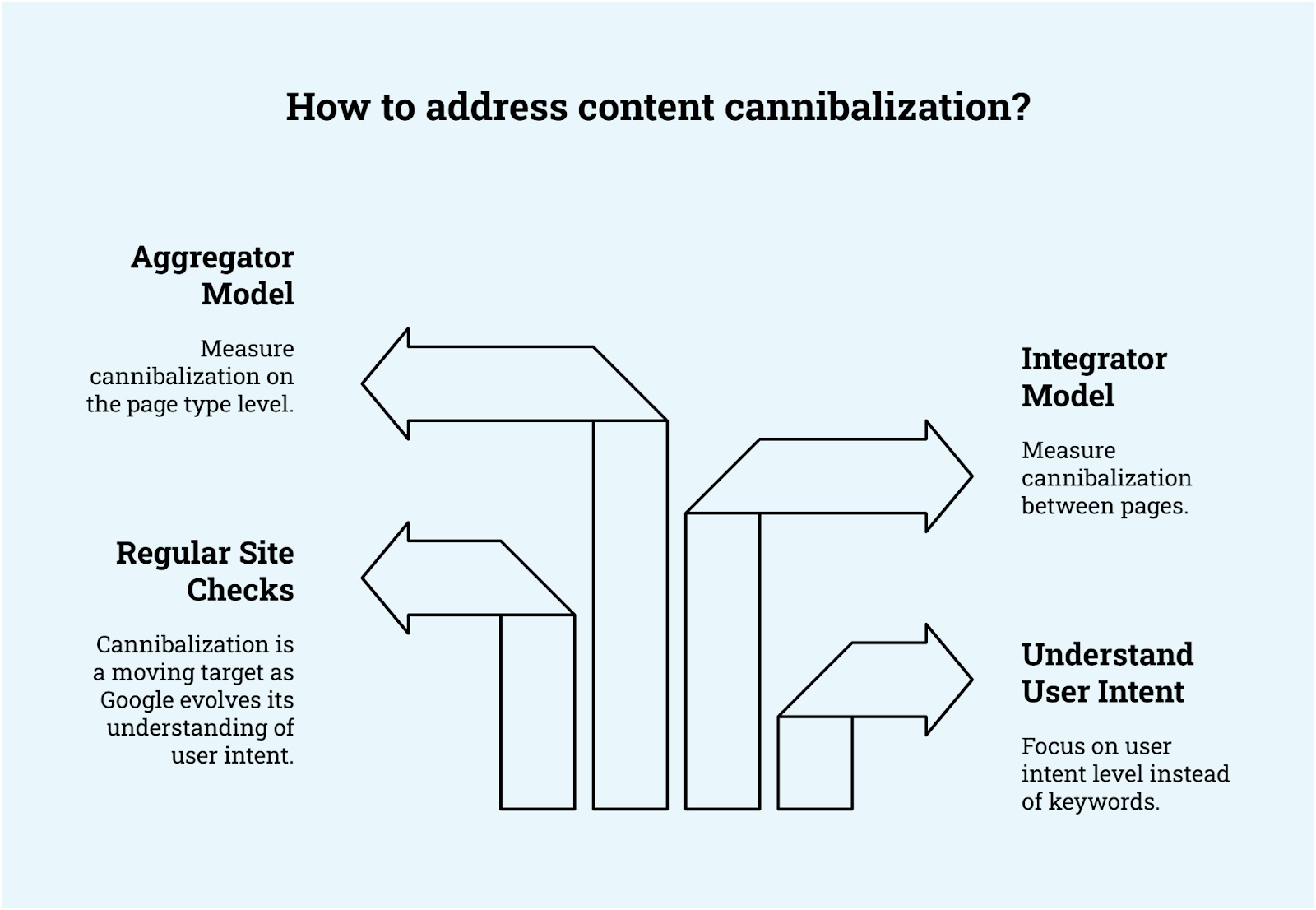
Mi modelo para los tipos de sitios es el modelo integrador frente a agregador. Los minoristas en línea y otros mercados se enfrentan a casos de canibalización fundamentalmente diferentes a los de las empresas SaaS o D2C.
Los integradores canibalizan entre páginas. Los agregadores canibalizan entre tipos de páginas.
Con los agregadores, la canibalización suele producirse cuando dos tipos de páginas son demasiado similares. Por ejemplo, puedes tener dos tipos de páginas que podrían o no competir entre sí: «puntos de interés en {ciudad}» y «cosas que hacer en {ciudad}».
Con los integradores, la canibalización suele producirse cuando las empresas publican contenido nuevo sin mantenimiento ni un plan para el contenido existente. Gran parte del problema radica en que cada vez es más difícil tener una visión general de lo que tienes y de las palabras clave/intención a las que se dirige un determinado número de artículos (yo he descubierto que el punto de inflexión está en torno a los 250 artículos).
Cómo detectar la canibalización de contenidos
Un ejemplo de canibalización de contenidos
La canibalización de contenidos puede presentar uno o más de los siguientes síntomas:
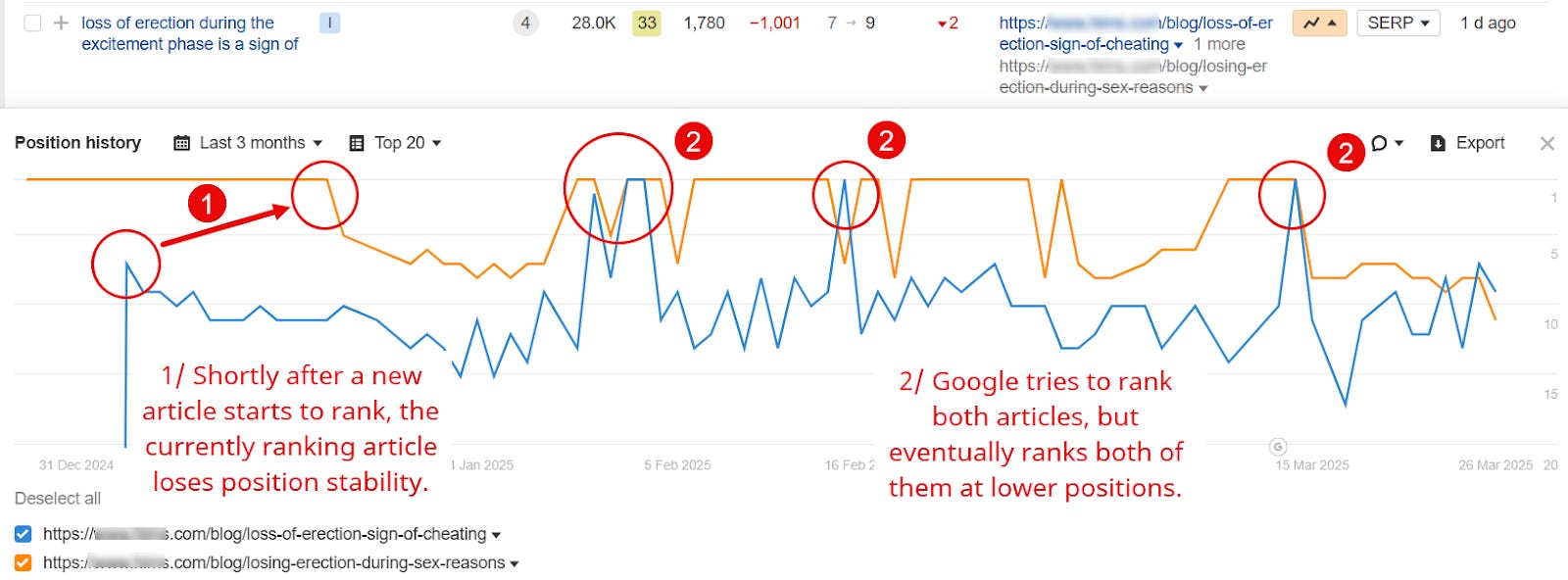
«Parpadeo de URL»: significa que al menos dos URL se alternan en el ranking para una o más palabras clave.
Una página pierde tráfico y/o posiciones en el ranking después de que se publique otra.
Una nueva página alcanza una meseta de posicionamiento para su palabra clave principal y no puede entrar en las 3 primeras posiciones.
Google no indexa una nueva página o páginas dentro del mismo tipo de página.
Aparecen títulos duplicados exactos en el índice de búsqueda de Google.
Google informa «rastreado, no indexado» o «descubierto, no indexado» para las URL que no tienen contenido escaso o problemas técnicos.
Dado que Google no nos da una señal clara de canibalización, la mejor manera de medir la similitud entre dos o más páginas es la similitud del coseno entre sus incrustaciones tokenizadas (lo sé, es un trabalenguas).
Pero esto es lo que significa: Básicamente, se compara lo similares que son dos páginas convirtiendo su texto en números y viendo cómo esos números apuntan en la misma dirección.
Piénsalo como una receta de galletas de chocolate:
Tokenización = Descomponer cada receta (por ejemplo, el contenido de la página) en ingredientes: harina, azúcar, chips de chocolate, etc.
Incrustaciones: convertir cada ingrediente en números, por ejemplo, cuánto se utiliza de cada ingrediente y qué importancia tiene cada uno para la identidad de la receta.
Similitud coseno: comparar las recetas matemáticamente. Esto te da un número entre 0 y 1. Una puntuación de 1 significa que las recetas son idénticas, mientras que 0 significa que son completamente diferentes.
Sigue este proceso para escanear tu sitio y encontrar candidatos a la canibalización:
Rastreo: rastrea tu sitio con una herramienta como Screaming Frog (opcionalmente, excluye las páginas que no tienen ningún propósito de SEO) para extraer la URL y el metatítulo de cada página.
Tokenización: convierte las palabras tanto de la URL como del título en fragmentos de palabras con los que sea más fácil trabajar. Estos son tus tokens.
Incrustaciones: convierte los tokens en números para hacer «cálculos de palabras».
Similitud: calcula la similitud del coseno entre todas las URL y metatítulos.
Lo ideal es que esto te dé una lista de URL y títulos que son demasiado similares.
En el siguiente paso, puedes aplicar el siguiente proceso para asegurarte de que realmente se canibalizan entre sí:
Extraer contenido: Aísla claramente el contenido principal (excluye navegación, pie de página, anuncios, etc.). Tal vez limpiar ciertos elementos, como palabras vacías.
Fragmentación o tokenización: o bien dividir el contenido en fragmentos significativos (frases o párrafos) o tokenizar directamente. Yo prefiero lo segundo.
Incrustaciones: incrustar los tokens.
Entidades: extraer entidades nombradas de los tokens y ponderarlas más en las incrustaciones. En esencia, compruebas qué incrustaciones son «cosas conocidas» y les das más peso en tu análisis.
Agregación de incrustaciones: Agrega incrustaciones de tokens/fragmentos con un promedio ponderado (por ejemplo, TF-IDF) o agrupación ponderada por atención.
Similitud coseno: Calcula la similitud coseno entre las incrustaciones resultantes.
Puedes usar mi script de aplicación si quieres probarlo en Google Sheets (pero tengo una alternativa mejor para ti en un momento).
Acerca de la similitud coseno: No es perfecta, pero es lo suficientemente buena.
Sí, puedes ajustar los modelos de incrustación para temas específicos.
Y sí, puedes usar modelos de incrustación avanzados como transformadores de oraciones en la parte superior, pero este proceso simplificado suele ser suficiente. No hay necesidad de hacer un proyecto de astrofísica con ello.
Cómo solucionar la canibalización
Una vez que hayas identificado la canibalización, debes tomar medidas.
Pero no olvides ajustar tu enfoque a largo plazo para la creación y gestión de contenidos. Si no lo haces, todo este trabajo para encontrar y solucionar la canibalización será en vano.
Solucionar la canibalización a corto plazo
Las medidas a corto plazo que debes tomar dependen del grado de canibalización y de la rapidez con la que puedas actuar.
El «grado» se refiere a la similitud del contenido entre dos o más páginas, expresada en coseno o similitud de contenido.
Aunque no es una ciencia exacta, en mi experiencia, una similitud de coseno superior a 0,7 se clasifica como «alta», mientras que es «baja» por debajo de un valor de 0,5.

4 formas de solucionar la canibalización
Qué hacer si las páginas tienen un alto grado de similitud:
Canonicaliza o no indexa la página cuando la canibalización se produce debido a problemas técnicos como las URL de parámetros, o si la página canibalizadora es irrelevante para el SEO, como las páginas de destino de pago. En este caso, canonicaliza la URL de parámetros a la URL sin parámetros (o no indexa la página de destino de pago).
Consolida la página con otra cuando no se trate de un problema técnico. La consolidación consiste en combinar el contenido y redirigir las URL. Te sugiero que tomes la página más antigua o la que tenga peor rendimiento y la redirijas a una nueva y mejor. A continuación, transfiere cualquier contenido útil a la nueva variante.
Qué hacer si las páginas tienen un bajo grado de similitud:
Noindex o eliminar (código de estado: 410) cuando no tengas la capacidad o habilidad para realizar cambios en el contenido.
Desambiguar el enfoque de la intención del contenido si tienes la capacidad, y si el solapamiento no es demasiado fuerte. En esencia, quieres diferenciar las partes de las páginas que son demasiado similares.
Resolver la canibalización a largo plazo
Es fundamental tomar medidas a largo plazo para ajustar tu estrategia o proceso de producción porque la canibalización de contenidos es un síntoma de un problema mayor, no una causa fundamental.
(A menos que estemos hablando de que Google cambie su comprensión de la intención durante una actualización del algoritmo principal, y eso no tiene nada que ver contigo o con tu equipo).
Los cambios a largo plazo más importantes que debes realizar son:
Crear una hoja de ruta de contenidos: los integradores de SEO deben mantener una hoja de cálculo o base de datos viva con todas las URL relevantes para el SEO y sus principales palabras clave e intención de destino para reforzar la supervisión editorial. Quien esté a cargo de la hoja de ruta de contenidos debe asegurarse de que no haya superposición entre los artículos y otros tipos de páginas. Los escritores deben tener una intención de destino clara para el contenido nuevo y el existente.
Desarrolla una arquitectura de sitio clara: El complemento de un mapa de contenido para agregadores SEO es un mapa de arquitectura de sitio, que es simplemente una visión general de los diferentes tipos de páginas y la intención a la que se dirigen. Es fundamental subrayar la intención tal y como la defines con palabras clave de ejemplo que verifiques regularmente («¿Seguimos posicionando bien para esas palabras clave?») para compararla con la comprensión de Google y la de los competidores.
La última pregunta es: «¿Cómo sé cuándo se ha solucionado la canibalización de contenidos?».
La respuesta es cuando desaparecen los síntomas mencionados en el capítulo anterior:
Se resuelven los problemas de indexación.
Desaparece el parpadeo de la URL.
No aparecen títulos duplicados en el índice de búsqueda de Google.
Disminuyen los problemas de «rastreado, no indexado» o «descubierto, no indexado».
Las clasificaciones se estabilizan y superan un estancamiento (si la página no tiene otros problemas aparentes).
Y, después de trabajar con mis clientes bajo este marco manual durante años, decidí que era hora de automatizarlo.
Presentamos: un detector de canibalización totalmente automatizado.
Junto con Nicole, utilicé AirOps para crear un flujo de trabajo de IA totalmente automatizado que sigue 37 pasos para detectar la canibalización en cuestión de minutos.
Realiza un análisis exhaustivo de la canibalización de contenidos examinando las clasificaciones de palabras clave, la similitud de los contenidos y los datos históricos.
A continuación, desglosaré los pasos más importantes que automatiza en tu nombre:
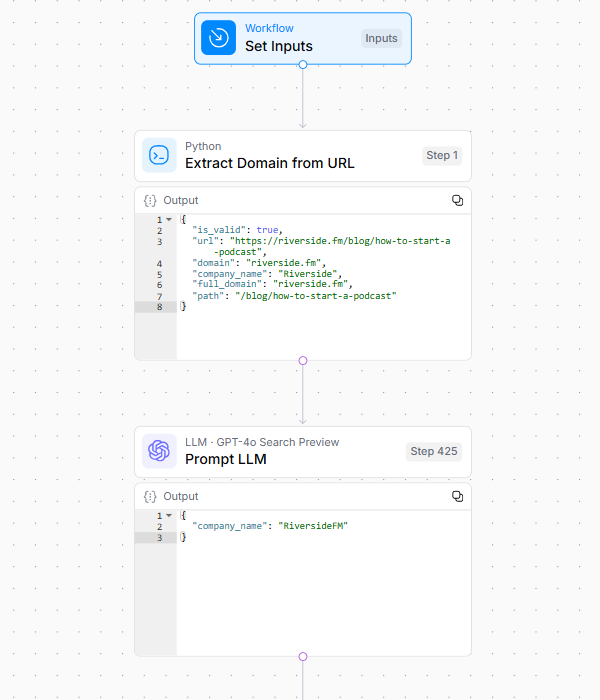
1. Procesamiento inicial de la URL
El flujo de trabajo extrae y normaliza el dominio y el nombre de la marca de la URL de entrada.
Este paso fundamental establece la identidad del sitio web de destino y crea la línea de base para todos los análisis posteriores.
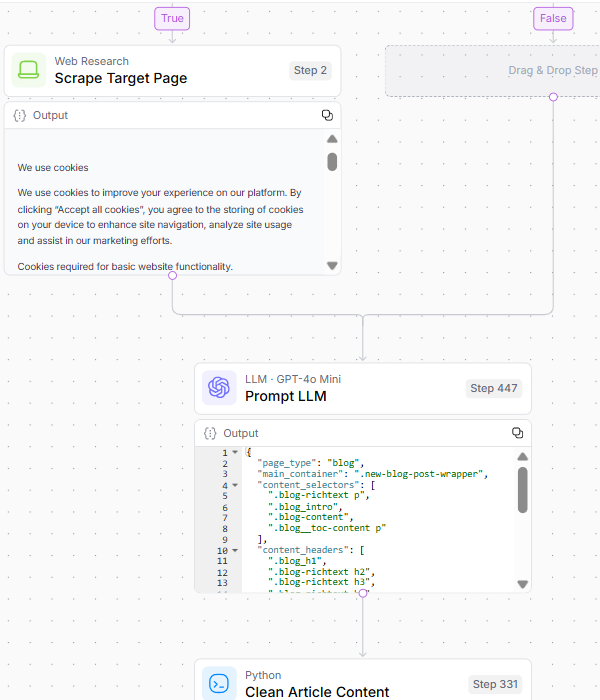
2. Análisis del contenido de destino
Para garantizar que el sistema disponga de material de origen de calidad para analizar y comparar con la competencia, el paso 2 implica:
Raspar la página
Validar y analizar la estructura HTML para la extracción del contenido principal
Limpiar el contenido del artículo y generar incrustaciones de destino.
3. Análisis de palabras clave
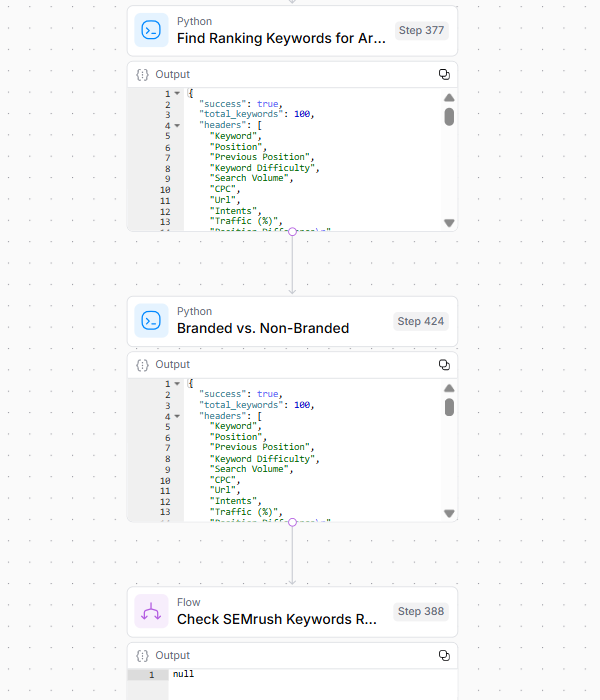
El paso 3 revela la visibilidad de búsqueda de la URL de destino y las posibles vulnerabilidades mediante:
Analizando las palabras clave de clasificación a través de los datos de SEMrush
Filtrando los términos de marca frente a los términos sin marca
Identificando la superposición de SERP con URL de la competencia
Realizando un análisis histórico de la clasificación
Determinando el valor de la página en función de múltiples métricas
Analizando los cambios diferenciales de posición a lo largo del tiempo.
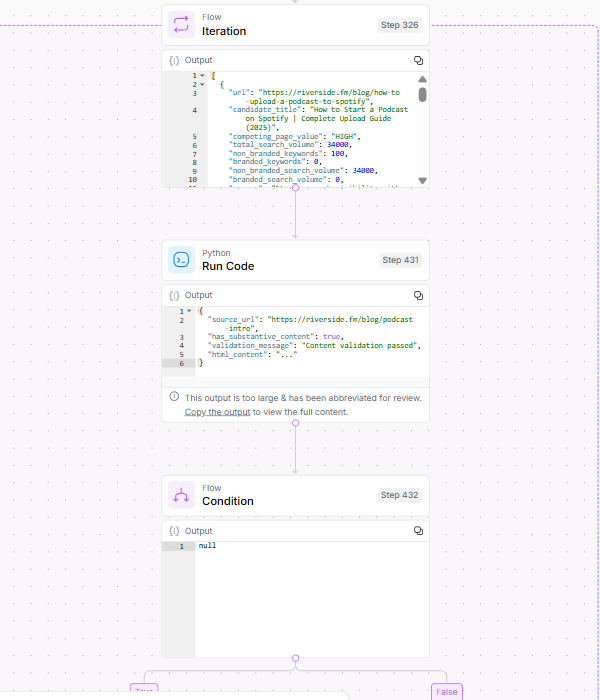
4. Análisis de contenido de la competencia (Iteración sobre URL de la competencia)
El paso 4 recopila contexto adicional para la canibalización mediante el procesamiento iterativo de cada URL de la competencia en los resultados de búsqueda a través de los pasos anteriores.
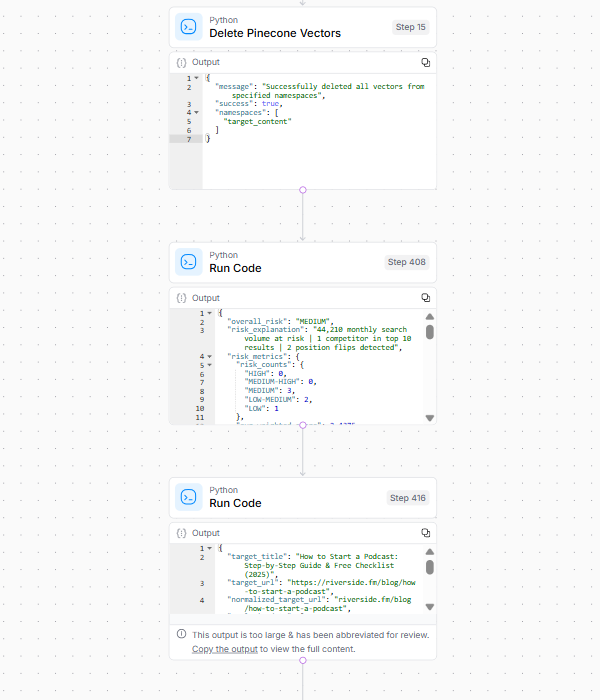
5. Generación del informe final
En el paso final, el flujo de trabajo limpia los datos y genera un informe procesable.
Prueba el Detector de canibalización de contenido automatizado
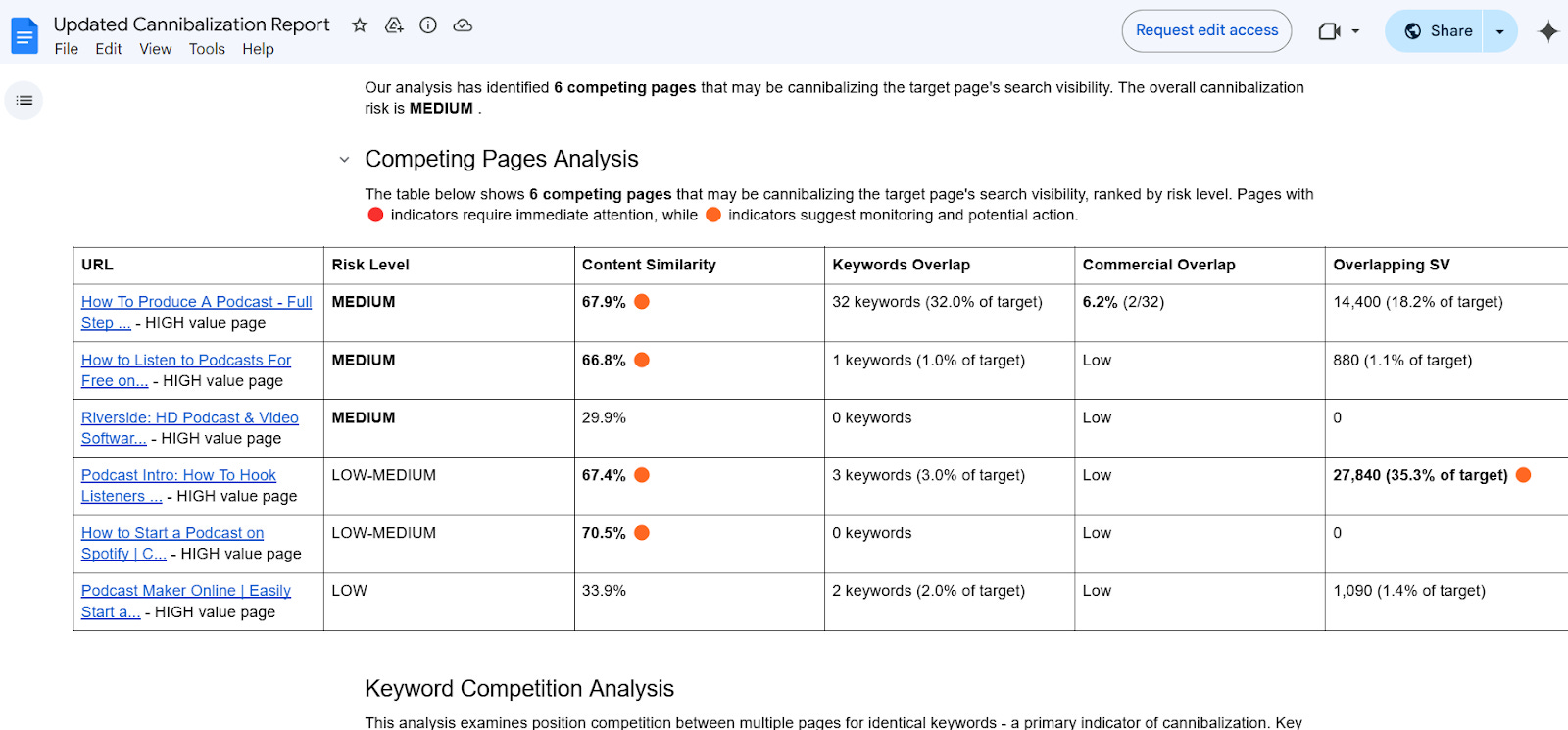
Prueba el Detector de canibalización y consulta un ejemplo de informe.
Algunas cosas a tener en cuenta:
Esta es una versión preliminar. Tenemos previsto optimizarla y mejorarla con el tiempo.
El flujo de trabajo puede agotar el tiempo de espera debido a un gran número de solicitudes. Limitamos intencionadamente el uso para no sobrecargarnos con llamadas a la API (cuestan dinero). Supervisaremos el uso y es posible que aumentemos temporalmente el límite, lo que significa que si tu primer intento no tiene éxito, inténtalo de nuevo en unos minutos. Puede que solo sea un pico temporal de uso.
Soy asesor de AirOps, pero no me han pagado ni me han incentivado de ninguna otra manera para crear este flujo de trabajo.
Por favor, deja tus observaciones en los comentarios.
También puede interesar:

Qué obtienen los lectores de Growth Memo:
Marcos: cómo abordar las decisiones estratégicas sobre el crecimiento orgánico, por ejemplo, cómo evaluar el verdadero potencial comercial del SEO para diferentes tipos de empresas.
Modelos mentales: patrones y principios que Kevin ha reconocido en diferentes empresas y situaciones.
Herramientas de decisión: enfoques para tomar mejores decisiones estratégicas sobre el crecimiento orgánico, como la asignación de recursos, el tiempo o la evaluación de riesgos.
Datos: estadísticas, estudios de casos y números que explican y grafican las tendencias que los responsables de la toma de decisiones necesitan conocer.
Escenarios reales: escenarios anónimos del trabajo del asesor de Kevin para destacar el proceso de pensamiento estratégico y los marcos en acción.